GIOS Lecture Notes - Part 2 Lesson 4 - Thread Design Considerations
Review of kernel vs user level threads
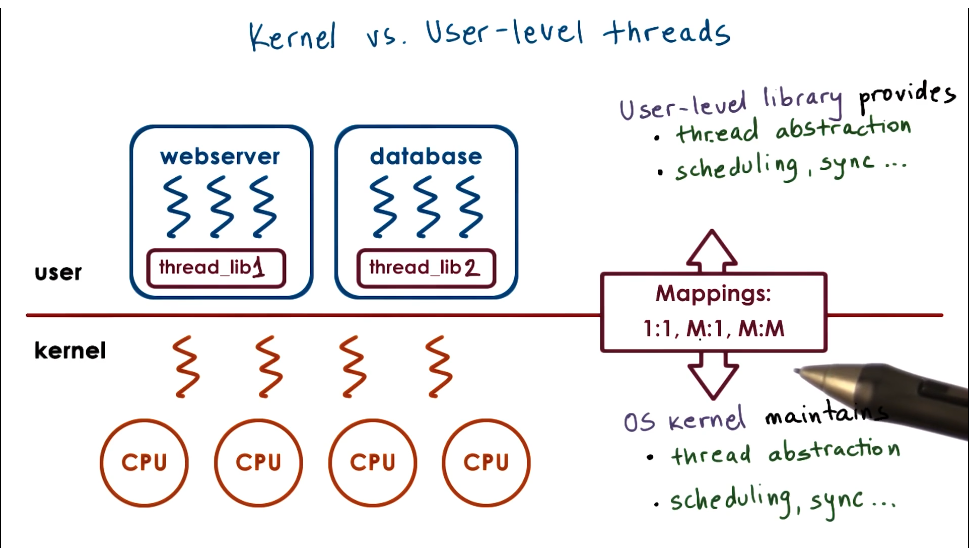
- When converting a program to multithreaded, if you want to match user level threads to multiple kernel level threads, you don’t want to have to duplicate the whole PCB for every thread.
- One solution is to split out the virtual address mapping (in PCB) from the stack and registers (in kernel level thread)
Thread Data Structures: at Scale
- Need copies of various structures for multiple threads and processes
- So, need to maintain relationships among them
- User level thread (ULT) keeps track of state of all user level threads
- Process Control Block (PCB) keeps track of virtual address mappings and some other state for all processes
- Kernel level thread (KLT) keeps track of state of kernel level threads executing on behalf of each process
- CPU - if multiple CPUs need structure to represent CPU and maintain relationship between CPU and KLT
- pointer to current and other threads
Hard and Light Process State
- Hard process state is relevant for all user level threads in a process
- Light process state is only relevant for a subset of user level threads in a process.
- Store them separately

Rationale for Data Structures
- Single PCB
- large continuous data structure
- private for each entity
- saved and restored on each context switch
- update for any changes
- Many cons
- scalability
- overhead
- performance
- flexibility
- Mutiple data stuctures
- smaller data structures
- easier to share
- on context switch only save and restore waht needs to change
- user-level library need only update portion of the state
- overall better than single PCB approach
Solaris Multithreading
User level thread data structures
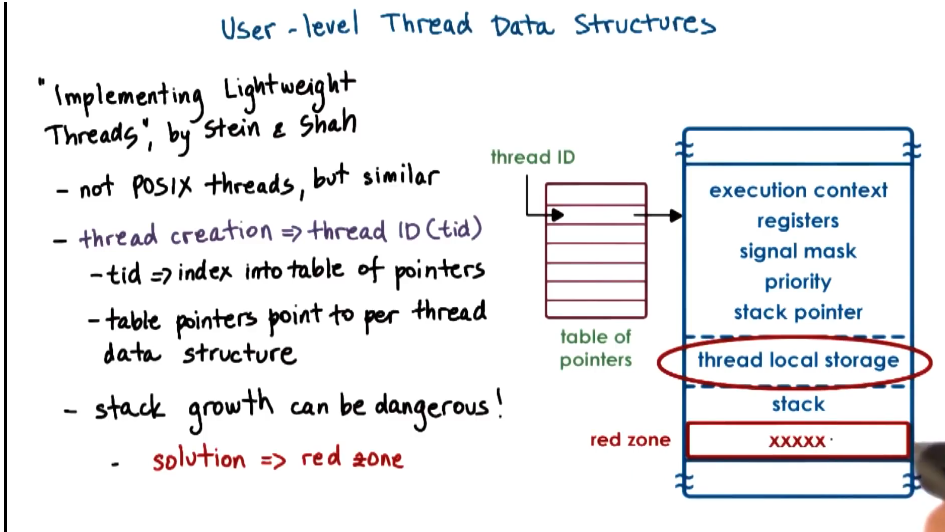
- Most of these attributes are known at compile time, so we can allocate the right size and a thoughtful layout for this data
- Stack growth can be dangerous as it is not known at compile time, and one thread’s stack might overflow into another thread’s data
- Debugging this is particularly nasty, as error appears when the second thread runs, even though the problem is within the first thread.
- Solution is a red zone that will cause faults within first thread if written into
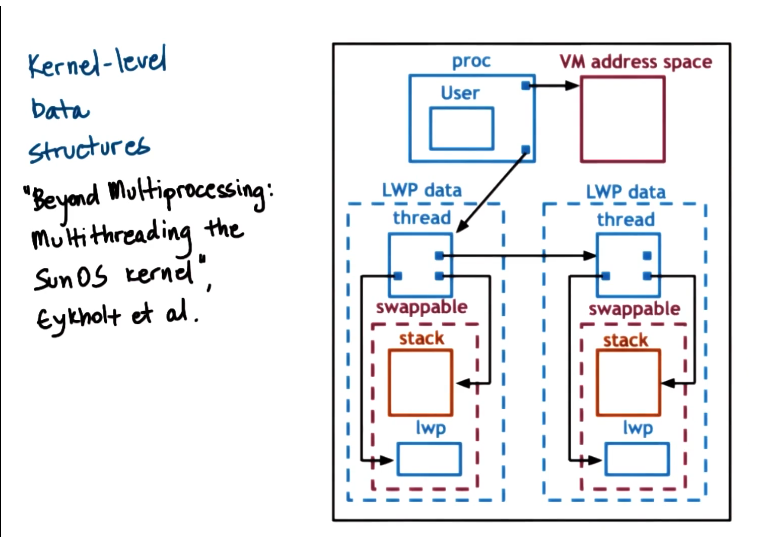
Kernel level data structures
- Process
- list of kernel level threads
- virtual address space
- user credntials
- signal handlers
- Light Weight Process (LWP)
- user level registers
- system call args
- resource usage info
- signal mask
- similar to ULT, but visible to kernel
- not needed when process not running -> swappable
- Kernel level threads (KLT)
- kernel level registers
- stack pointer
- scheduling info
- pointers to associated LWP, process, CPU structures
- information needed even when process not running -> not swappable
- CPU
- current thread
- list of KLT
- dispatching and interrupt handling information
- on SPARC - dedicated reg == current thread
Basic Thread Management Interactions
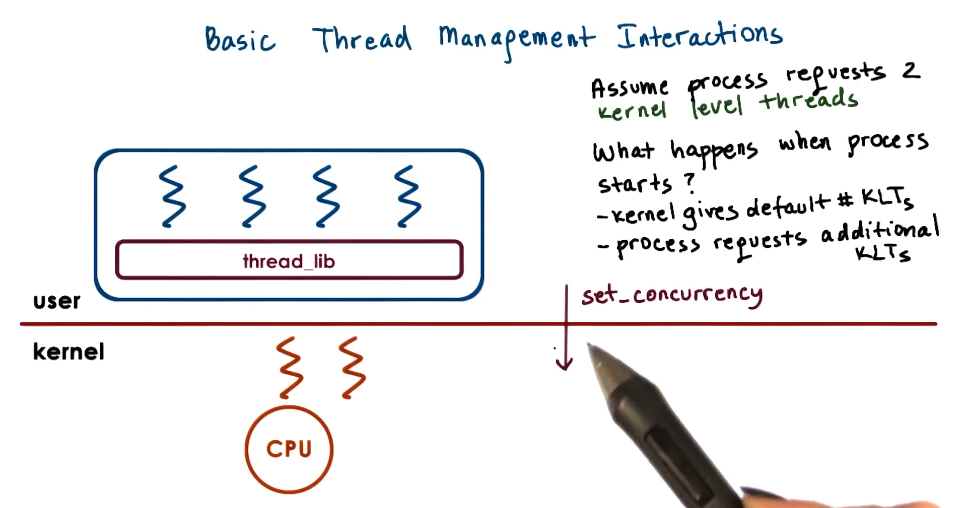
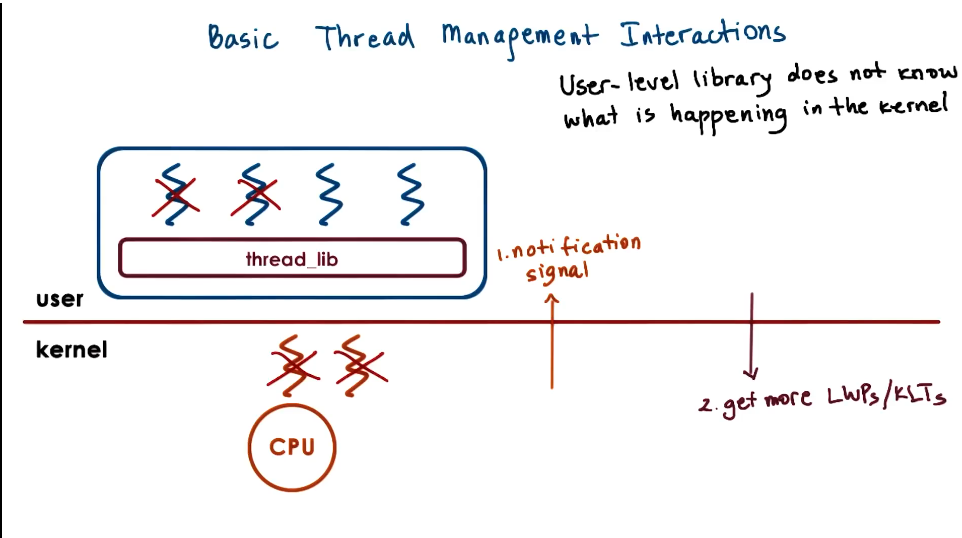
- User level library does not know what is happening in the kernel
- Kernel does not know what is happening in user level library
- System calls and special signals allow kernel and ULT library to interact and coordinate
Thread Management Visibility and Design
- Kernel sees
- KLTs
- CPUs
- KL Scheduler
- UL Library sees
- ULTs
- available KLTs
- in M:1 models there is a lack of visibility between KLT and ULT, data structures and details hampers both when interacting. One to one models addresses much of this
Issues on Multiple CPUs
- Can have issues when one thread on one CPU needs to have impact on the state or execution of another thread on another CPU
- For example, if Thread A needs to pre-empt Thread B across CPUs
- To do this you have to pass interrupts across CPUs and prompt execution of library code
Synchronization Related Issues
- In multi-CPU case described above, if the critical secion is short it actually takes more time to communicate back and forth.
- In this case don’t block, just spin on the mutex
- for long critical sections normal blocking is correct
- Mutexes that can either block or spin in this way are called adaptive mutexes
- Destroying threads
- Instead of destroying, you can reuse threads to avoid creation and destruction overhead
- To do this, when a thread exits
- it’s put on a death row
- periodically destroyed by reaper thread
- if a request for a thread comes in before reaping, then thread structures / stacks are reused -> performance gains!
Interrupts and Signals Intro
- Interrupts
- events generated externally to a CPU by components other than the CPU (IO devices, timers, other CPUs)
- represent some notification to the CPU that some external event has occurred
- determined by the physical platform
- appear asynchronously
- Signals
- events triggered by the CPU and software running on it
- determined by the operating system
- Interrupts and Signals Both:
- have a unique ID depending on the hardware or OS
- can be masked and disabled/suspended via corresponding mask
- per-CPU interrupt mask
- per-process signal mask
- if enabled, trigger corresponding handler
- interrupt handler set for entire system by OS
- signal handlers set on per process basis, by process
Interrupt Handling
- Hardware maintains table of INT# indicators, which maps to OS-defined actions for each available interrupt
Signal Handling
- OS maintains a list of Signals. Also maintains, for each process, a mapping of each signal to correct actions.
- Example given in lecture is SIGSEGV for illegal memory access, signal #11.
- Handlers/Actions
- Default Actions - terminate, ignore, terminate and core dump, stop, continue
- Process installs handler
- signal(), sigaction()
- for most signals, some cannot be “caught”
- Example Signals
- Synchronous
- SIGSEGV (access to protected memory)
- SIGFPE (divide by zero)
- SIGKILL (kill, id)
- can be directed to a specific thread
- Asynchronous
- SIGKILL (kill)
- SIGALARM
- Synchronous
Why Disable Interrupts or Signals?
- There is a problem with both, in that they’re executed within the context of the thread that was interrupted
- Very easy for signal handler in thread to deadlock trying for a mutex that the problem thread was already holding
- One solution is to just disallow mutexes in the handler code
- too restrictive
- control interruptions by handler code
- use interrupt/signal masks
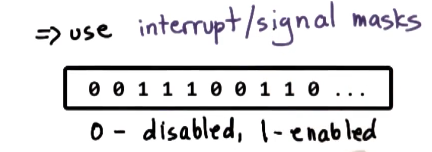
- whenever an interrupt is considered, check mask and do not interrupt if disabled. have handler run later when mask value changes
- One solution is to just disallow mutexes in the handler code
- Interrupt masks are per CPU
- if mask disables interupt, hardware interrupt routing mechanism will not deliver interrupt to CPU
- Signal masks are per execution context (ULT on top of KLT)
- if mask disables signal, kernel sees mask and will not interrupt corresponding thread
Interrupts on Multicore Systems
- Interrupts can be directed to any CPU that has them enabled
- may set interrupt on just a single core
- avoids overheads and perturbations on all other cores. Improves performance
Types of Signals
- One-shot signals
- “n signals pending == 1 signal pending”: only one execution of handler is performed regardless of how many signals received
- must be explicitly re-enabled after handling routine is called
- Real Time Signals
- “if n signals raised, then handler is called n times”
Interrupts as Threads
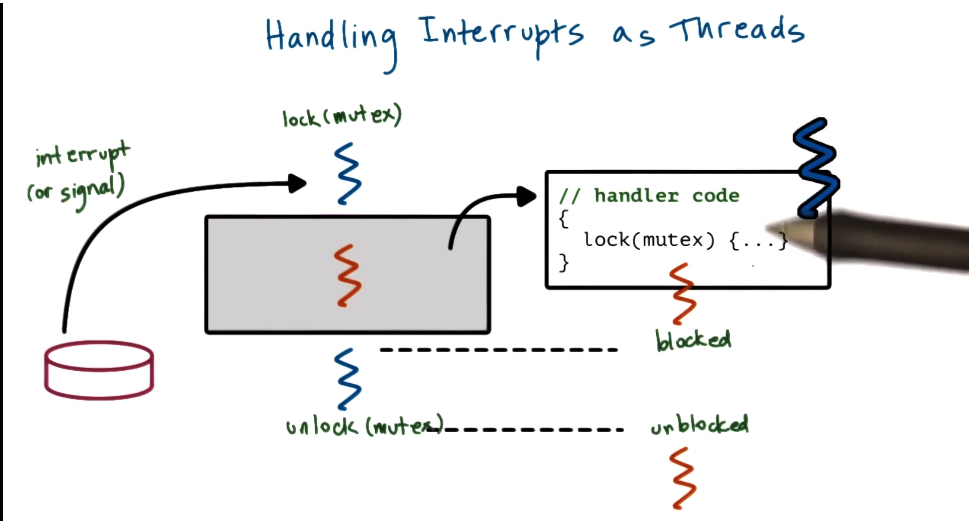
- one concern is that dynamic thread creation is expensive
- decision to be made is whether to handle the interrupt on the stack of the original process or move to its own thread with its own execution context
- Heuristic is:
- if handler doesn’t block => execute on interrupted thread’s stack
- if handler can block => turn into real thread
- Optimization
- pre-create and pre-initialize thread structures for interrupt routines
Interrupts: Top vs Bottom Half
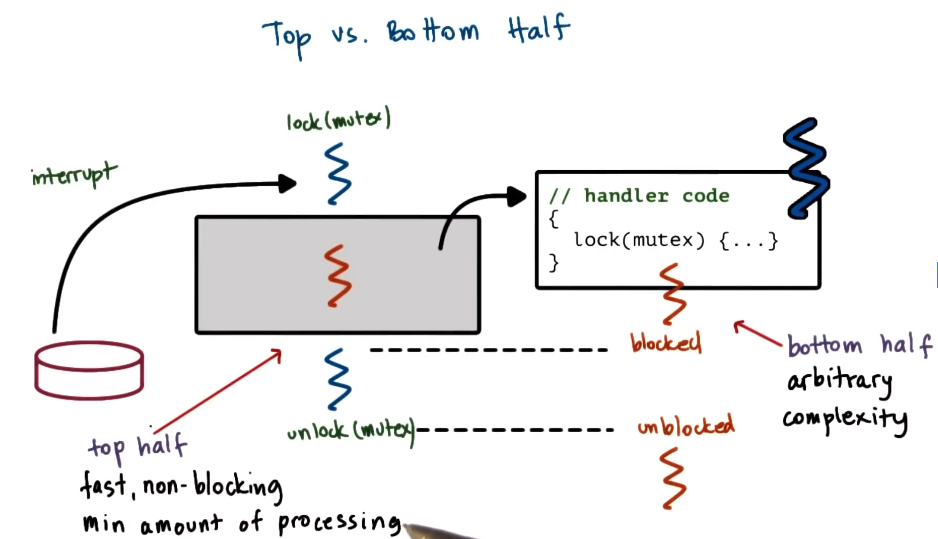
- split interrupt handling into a top half that follows restrictive non blocking tools
- and bottom half that is arbitrarily complex, can use all tools, and can be subjected to synchronization techniques
- Discussed in detail in the Solaris paper, including coverage of priority levels for both parts
Performance of Threads as Interrupts
- Overall cost
- overhead of 40 SPARC instructions per interrupt
- saving of 12 instructions per mutex
- no changes in interrupt mask, level
- fewer interrupts than mutex/lock unlock operations
- overall a performance win
- Optimize for the common case!
- Common case here is mutex lock/unlock, so focus on those and be willing to pay a price elsewhere
Threads and Signal Handling
- ULT has a mask associated with it, visible to ULL
- KLT has a mask associated with LWP it’s attached to, visible to Kernel
- Can have masks on KLT and ULT disagree with each other
- Need a policy solution to avoid syscalls every time ULT mask is changed
- Proposed in Solaris papers
Case 1
- If KLT and ULT signal masks both enabled and signal happens
- Kernel sees that the signal is enabled
- Interrupts currently running ULT
- No problem, as ULT had signal enabled also
Case 2
- If KLT has mask enabled, ULT 1 has mask disabled, and another ULT 2 (not executing, just in run queue) has mask enabled
- ULT library knows about second thread and its mask
- So Kernel will pass signal to threading library by specifying a signal that calls ULT library handling routine
- ULT library will pass signal over to ULT 2 and thus allow it to be handled
Case 3
- If there are two KLT with mask enabled, ULT 1 has mask disabled, and ULT 2 (running on KLT 2 on another CPU) has mask enabled
- when signal is delivered in KLT 1 the ULT library will see that ULT 2 is running on KLT 2, and send a directed signal to KLT 2
- Then KLT 2 will see mask enabled, pass up to ULT library, which will see ULT 2 mask enabled, and then execute signal handler
Case 4
- If there are two KLT with mask enabled, and two ULT on separate KLT both with mask disabled
- When signal occurs, kernel sees mask is enabled, and sends signal up to ULT library.
- ULT library sees that ULT 1 has mask disabled and that no other threads have mask enabled.
- Thus ULT library will send syscall back down to kernal to disable mask for KLT 1
- Kernel will find another KLT with mask enabled and try again, sending signal
- Process repeats, and KLT 2 mask will be set to 0. Repeat for each available KLT
- If a ULT finishes its block and enables mask again, ULT Library will perform a syscall and update KLT mask to enabled again
- This seems inefficient at first glance, but is another example of optimizing for the common case
- Signals are less frequent than signal mask updates
- System calls avoided - cheaper to update UL mask
- Signal handling more expensive, but it happens infrequently so it’s still an overall win
Tasks in Linux
Task Struct in Linus
- main execution abstraction == Task
- KLT
- single threaded process has 1 task
- multi threaded process has many tasks, 1 per thread

- task identifier is housed in pid, legacy reasons
- group of tasks identified by original task created in tgid
- maintains list of tasks that are part of single process
- Learning from previous implementations, Linux never had one contiguous PCB
- Instead process state is represented through a collection of references to data structures
- Referenced via pointers
- Makes it easy for tasks in a single process to share some portions of the address space such as files or similar
- Instead process state is represented through a collection of references to data structures
- To create a new task, Linux supports the clone() function
- clone(function, stack_ptr, sharing_flags, args)
- Similar to pthread_create

- sharing_flags: basically if all flags are set it’s a complete copy of parent, while if no flags are set it’s almost a fork
- fork() is actually implemented via clone() internally
- fork() is very different for multi threaded vs single threaded processes
- for single threaded we expect child process will be a full replica of parent process
- for multi threaded we expect the child to be a single threaded process, a replica of only portion of address space visible to parent thread
- Similar to pthread_create
- clone(function, stack_ptr, sharing_flags, args)
- Linux Threads Model
- Linux uses the Native POSIX Threads Librar (NPTL) which is a 1:1 model where every ULT has a KLT to associate to
- kernel sees each ULT info
- kernel traps have become much cheaper with hardware evolution
- more resources: memory, large range of IDs
- generally the performance hit for 1:1 is now a smaller problem than the complexity of M:M
- Oldter LinxuThreads was a M:M model
- similar issues to those described in Solaris papers
- Linux uses the Native POSIX Threads Librar (NPTL) which is a 1:1 model where every ULT has a KLT to associate to