GIOS Lecture Notes - Part 4 Lesson 2 - Distributed File Systems
Distributed File Systems
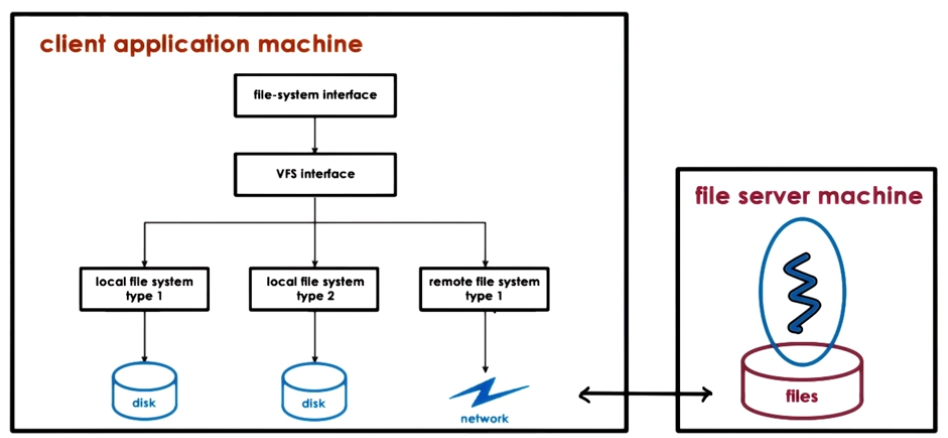
- Modern OS’s hide the implementation details of individual file systems and storage devices using a Virtual File System (VFS) interface
- This can also hide the complete lack of any local storage, and everything is being stored in a remote machine
- This is the basis of a distributed file system (DFS)
DFS Models
- DFS == A filesystem that can be organized in any of the following ways
- client/server are on different machines
- file server distributed on multiple machines
- replicated – each server has all files
- helps with failure resilience
- helps with availability, as all requests coming in can be split across different servers
- partitioned – each server has only some of the files
- more scalable. if you need to store more files just add more machines
- both/combo – files partitioned, each partition replicated across multiple machines
- files stored and served from all machines (peers)
- blurs the distinction between clients and servers
- p2p architecture baby
Remote File Service: Extremes
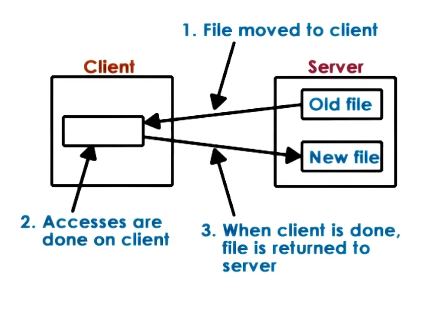
- Extreme 1: Upload/Download Model
- Like FTP, SVN, etc
- Pros
- local reads/writes at client – faster/simpler
- Cons
- client must download and upload the entire file, even for small accesses
- server gives up control and visibility into what’s done with the files
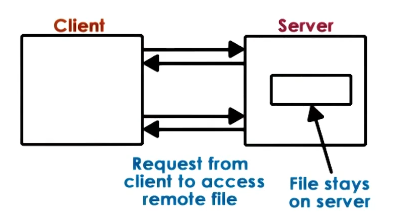
- Extreme 2: True Remote File Access
- Every access is done to remote file. nothing is done locally on client
- Pros
- file accesses centralized to server
- easy to reason about consistency
- Cons
- every single file operation incurs the cost of traversing the network
- limits server scalability
Remote File Service: A Compromise
- The above models are obviously suboptimal. A compromise is better. Should include caching
- Allow clients to store parts of files locally (blocks)
- prefetching techniques likely worthwhile here
- Pros
- lower latency on file operations
- server load reduced => more scalable
- Force clients to interact with the server (frequently)
- clients must notify server of any modifications they have made
- clients must find out from server if any files they have cached locally have been modified by someone else
- Pros
- server has insights into what clients are doing
- server has control over which accesses can be permitted, making it easier to maintain consistency
- Cons
- server more complex (additional tasks and state to provide consistency guarantees)
- requires different file sharing semantics than are needed in a traditional local file system
Stateless vs Stateful File Server
- Stateless == keeps no staate
- no information about which clients access which files, how many clients, etc
- every request has to be completely self-contained
- Pros
- No state being kept means resources are used to keep state on server side (CPU/MMU)
- On failure, just restart. No state means no state to lose on failure.
- clients would need to reissue failed requests, is all
- Cons
- Ok with extreme models, but cannot support “practical” model
- cannot support caching and consistency management
- Every request being self-contained also means more bits must be transferred to describe the request
- Stateful == keeps client state
- Needed for ‘practical’ model to track what is cached/accessed
- Pros
- Can support locking, caching, incremental operations
- Cons
- On failure all state is lost and must be recovered somehow
- Need checkpointing and recovery mechanisms
- Overheads to maintain state and consistency
- The amount and kind of overhead depends on caching mechanism and consistency protocol
Caching State in a DFS – Optimization
- Clients maintain some portion of state locally (e.g. file blocks)
- Client performs operations on cached state locally (e.g. open/read/write/etc)

- Requires coherence mechanisms
- clients 1 and 2 both cache a portion of file F
- client 2 has updated its cached copy of file F
- client 2 has notified the file server of these changes, and they are now synced
- the question then is how and when will client 1 find out about this?
- This problem is similar to maintaining cache coherence in shared-memory multiprocessors (SMPs)
- How
- SMP => write-update/write-invalidate
- When
- This would mean that whenever client 2 made changes to its file F that will be propagated to client 1 as either WU or WI message
- But given the network costs of distributed systems, this is likely impractical and maybe unneccessary
- How
- DFS => client-driven OR server-driven
- When
- on demand
- OR periodically
- OR on file open
- details depend on file sharing semantics
File Sharing Semantics on a DFS
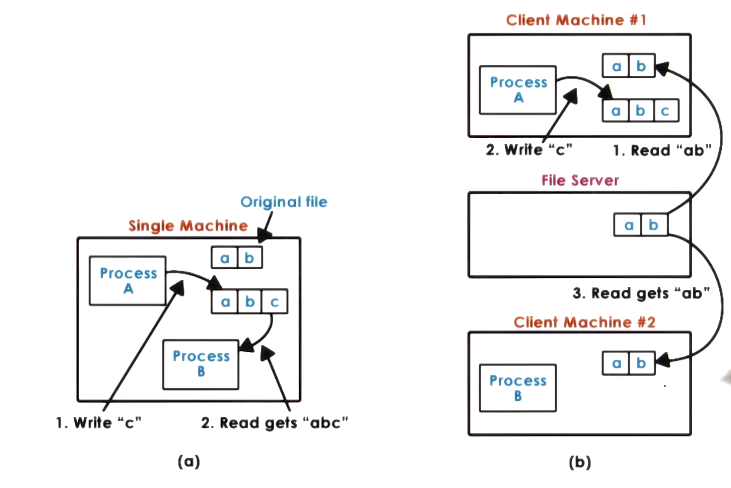
- On a local filesystem, changes are immediately visible. Any “write” function effects will be immediately in buffer cache and visible to any “read” function effects
- Obviously for DFS reads and writes are done locally, and will not be propagated to the server immediately, so it will function differently
- Given that message latencies will vary, we don’t know what delay would be appropriate to ensure reads will capture such changes
- Therefore, to maintain usable performance, DFS are forced to sacrifice some strictness in consistency requirements
- To handle these different constraints, new semantics are needed
- UNIX semantics => every write visible immediately
- Session semantics
- write-back changes to server on file close(), update changes from server on file open()
- period between open and close on a given client is a “session”
- easy to reason about but may be insufficient level of consistency
- particularly in use cases with long “sessions”
- Periodic updates
- client writes-back periodically
- clients have a “lease” on cached data (not necessarily exclusive lease)
- server invalidates periodically
- provides time bounds on “inconsistency”
- augment with flush()/sync() API
- client doesn’t have any idea about start/end times of periods, provide a mechanism to force a “reset” to a consistent state on demand
- Immutable Files
- never actually modify a file
- just delete or create files
- Transactions
- all changes are atomic
- filesystem must export an API so that clients can specify collection of files/operations that must be treated as a single transaction
File vs Directory Service
- Knowing the access patterns/workload for the expected use case
- sharing frequency
- write frequency
- importance of a consistent view
- Optimize for the common case!
- One problems that most FS’s have two different types of files with very different use cases.
- Regular Files
- Directories
- Choose different policies for each
- e.g. session-semantics for files, UNIX for directories
- e.g. less frequent periodic write-back for files than directories
Replication and Partitioning
- Replication
- each machine holds all files
- Pros
- load balancing (performance)
- availability
- fault tolerance
- Cons
- writes become more complex – not only do we have to worry about consistency among clients, now we need to sync between replicated servers too
- solution might be to write synchronously to all replicas
- this would slow down all writes
- or, write to one then propagate to all others
- replicas must be reconciled with each other
- e.g. voting – votes on “true” state taken from all servers and the majority wins
- Partitioning
- each machine has a subset of the files
- lots of options for deciding how best to apportion files
- Pros
- availability vs single server DFS
- scalability with file system size
- single file writes are simpler
- Cons
- on failure, lose portion of data
- load balancing is harder
- if you don’t load balance, hot spots and bottlenecks are possible
- Can combine both techniques
- files are partitioned into groups
- groups are then replicated
- lots of algorithms and options for how this might be done as well
- overall goal is to ensure sufficient fault tolerance while not overspending on storage
- also must balance partitions to ensure even load of size and access frequency
Networking File System (NFS) Design
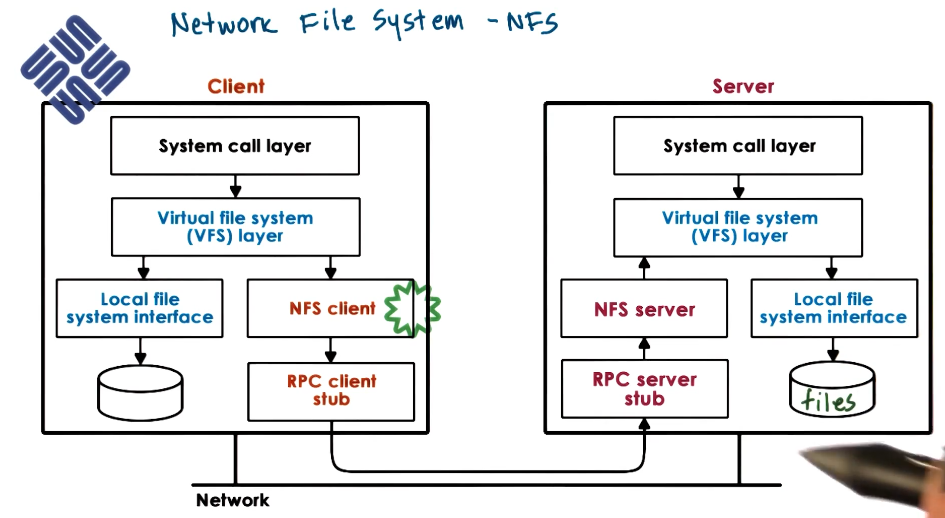
- A very popular commercial DFS by Sun
- Using file handle from NFS server if file is deleted or server goes down will result in an error. This is a “stale” handle.
NFS Versions
- Been around since the 80s. Currently on NFSv3 and NFSv4
- Key differeince is that NFSv3 is stateless, while NFSv4 is stateful
- caching
- session-based for files not accessed concurrently. On close() changes are flushed to disk
- periodic updates
- default: 3sec for files, 30sec for directories
- NFSv4 => delegation to client of all rights to manage a file for a period of time
- locking
- lease-based
- when a client acquires a lock the server acquires a time period for which the lock is valid
- it is the client’s responsibility to ensure that after this amount of time it either releases the lock or explicitly extends the lock duration
- helps address instances of client failure. lock will just time out. if returning, client will know that the lock expired and any changes must be re-done
- NSFv4 => also “share reservation” - reader/writer lock
- along with mechanisms for upgrading from reader to writer and vice-versa
Sprite Distributed File System
- Based on the Nelson et al paper - “Cashing in the Sprite Network File System”
- Sprite is a research system, but was used a bit
- great value in the explanation of the design process
- the authors used trace data on usage/file access patterns to analyze DFS design requirements and justify decisions
Access Pattern Analysis
- 33% of all file accesses are writes
- This is too much to just ignore
- Caching is OK, but write-through is not sufficient
- 75% of files are open less than 0.5sec
- 90% of files are open less than 10sec
- This means that session semantics will have too much overhead, won’t work here
- 20-30% of new data deleted within 30sec
- 50% of new data deleted within 5 minutes
- File sharing is rare!
- write-back on close not really necessary
- no need to optimize for concurrent access, but must support it
From Analysis to Design
- Based on the above analysis, Sprite went with the following design decisions
- Use cache with write-back policy
- every 30sec a client will write-back all the blocks that have NOT been modified for the last 30sec
- The logic is that anything currently being modified will continue being modified, so it’s a waste to do a write-back on those now. Instead wait a bit until it’s done.
- Related to the 20-30% deletion rate in a 30 second window above
- when another client opens a file currently being written, the server will query the writer client and collect/serve dirty blocks to the opener client
- it is possible writing was completed, there is no write-back on close policy
- All open ops go to server. This means directories are not cached on client
- on “concurrent writes” sprite disables caching for that file. all writes serialized on server side
- Sprite sharing semantics
- sequential write sharing == caching and sequential semantic
- concurrent write sharing == no caching
- this is infrequent, so the overall performance penalty is not significant
File Access Operations in Sprite
- N clients access files for reading, 1 writer client
- all open() calls go through server
- server will allow all accesses
- all clients cache blocks of the file
- writer client keeps timestamps for each modified block
- this is to enforce the write-back policy on any blocks not modified in the last 30sec
- sprite writer could close and re-open the file to continue editing an arbitrary number of times
- when it does this, the contents of the file are cached locally, but the open() still has to go to the server
- writer must compare cached value with the server. done with a version number
- client must keep track of some info for each file
- status (cached{y, n})
- cached blocks
- timer for each dirty block
- version
- status (cacheable{y, n})
- changed when/if caching is disabled for a given file
- server also keeps state for each file
- at some point after writer1 (w1) has closed file, writer2 (w2) wants to write file
- referred to as sequential sharing
- server contacts last writer for dirty blocks
- if w1 has closed server should update version and writer state
- w2 can now cache file
- while w2 is still writing to the file, w3 also wants to write to it
- referred to as concurrent sharing
- server contacts last writer (w2) for dirty blocks
- since w2 hasn’t closed the file, DISABLE CACHING for that file for all clients
- all subsequent file accesses must go to server
- now the server sees all accesses, so when the server sees that all but one client has closed the file, it can RE-ENABLE CACHING for that file